Warehouse vs Datalake Архитектура
Автор: S0ER
Основная задача разработки любой бизнес-системы сводится по сути к решению главного вопроса - как хранить много данных и иметь эффективный способ извлечения данных для аналитики. Для любой корпоративной системы вопрос хранения данных - это центральная точка проектирования.
В этом стриме я хочу поговогрить о двух основных подходах, используемых для хранения данных:
- Warehouse
- Datalake
выделить их различия, немного поговорить о основных характеристиках и помочь понять какие практические аспекты влияют на выбор архитектуры решения.
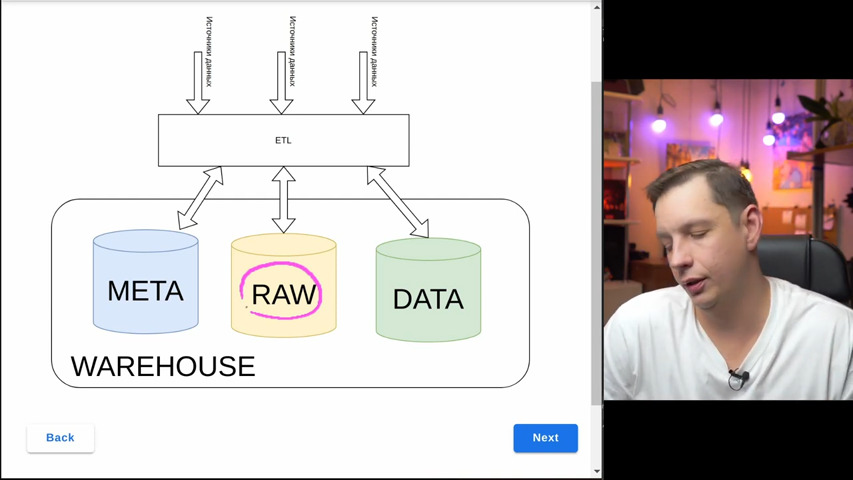
Типовая схема Warehouse решения
Duration: 10
Основные характеристики хранения данных:
- структурированность - все данные в СУБД должны быть жестко структурированы и подготовлены для хранения, это требование так же тесно связано с необходимостью единообразной обработки данных
- объем хранимых данных - обычно наращивается за счет подключения дискового массива и масштабируется вертикально
- скорость роста данных - количество данных, которые нужно хранить постоянно растет, поэтому у Warehouse решений всегда есть расчет на скорость роста данных, которые планируется хранить
Недостатки:
- структурированность:
- не соответствует современным тенденциям (сегодня прослеживается ориентация на JSON-документы)
- обработка на стороне СУБД, разветвленные хранимые процедуры, ограничения SQL
- объем хранения данных:
- скорость дисковых массивов ограничена
- размеры дисковых массивов ограничены
- скорость роста данных:
- нет возможности динамично наращивать объемы хранения, в соответствии с потребностью

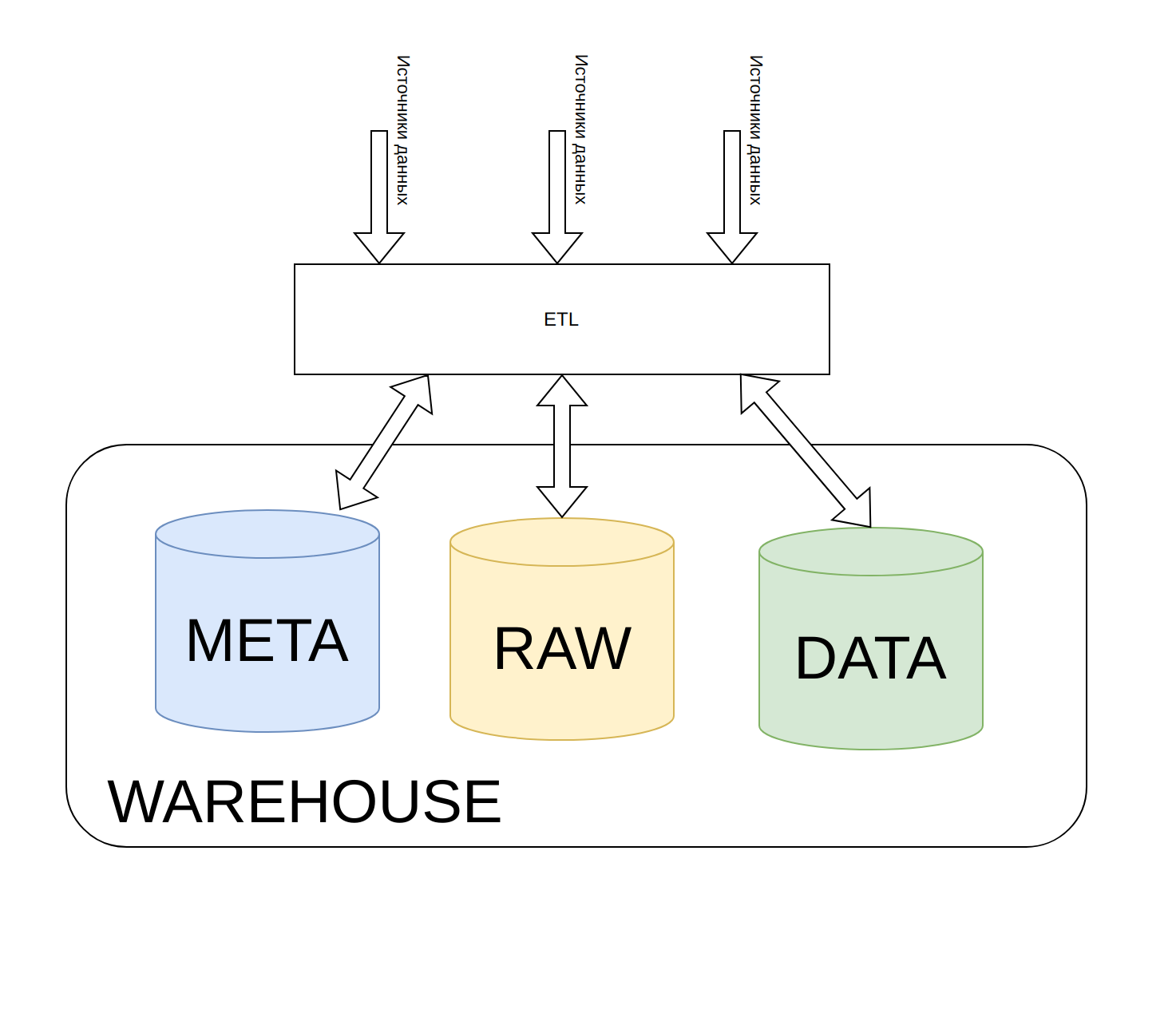
Расширенная схема Warehouse решения
Duration: 10
Общая схема конвейера DataLake
Duration: 10
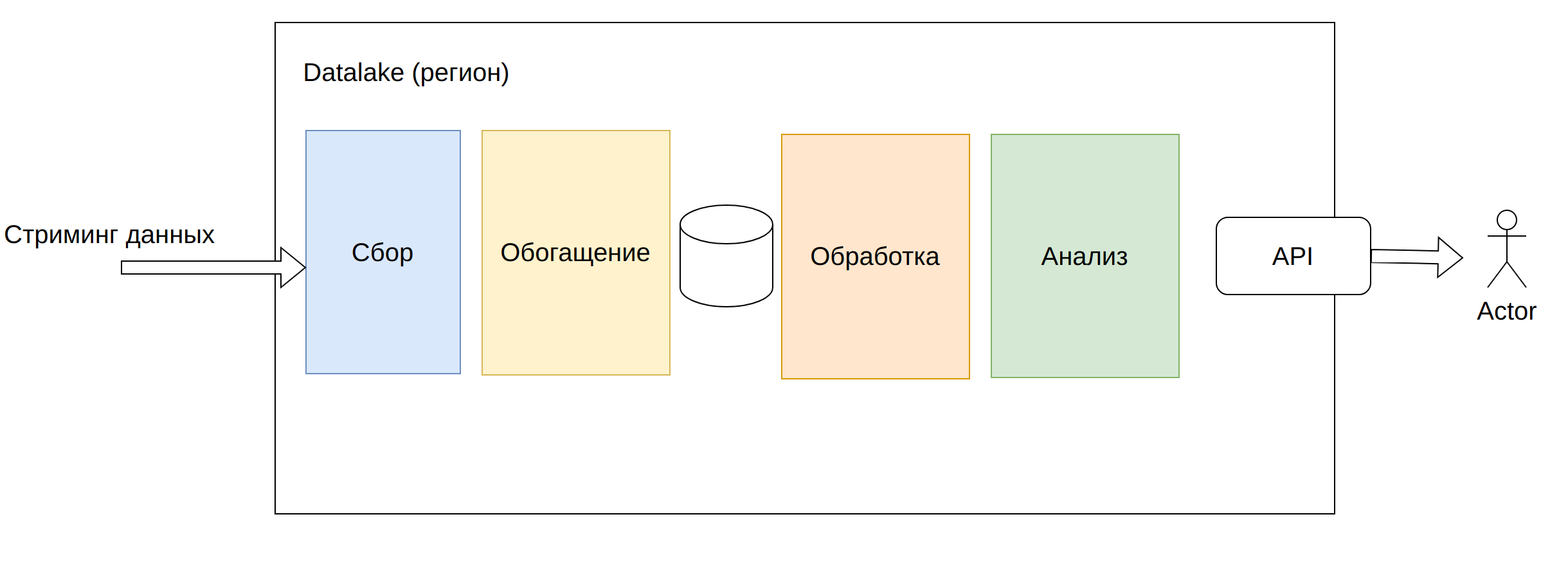
Сбор
Получение данных из разных источников. Поддерживаются разные варианты сбора: структурированный, неструктурированный, двоичный. Источниками данных могут выступать сторонние API и даже корпоративные хранилища данных.
Реализация хранения как правило - сетевые файловые хранилища, документооринтированные СУБД, распределенные файловые системы.
Обогащение
Слой отвечает за добавление метаинформации, необходимой для быстрого поиска сырых данных и для облегченной обработки этих данных в будущем. Кроме метаинформации может быть выполнена предварительная оптимизация или предобработка данных. Данные по-прежнему хранятся в "сыром" виде.
Реализация хранения как правило - сетевые файловые хранилища, документооринтированные СУБД, распределенные файловые системы.
Обработка
Уровень на котором происходит бизнес обработка данных. На этом этапе могут применяться распределенные вычисления (Map-Reduce алгоритмы и т.п.). Как правило результат данных более структурирован, чем входные данные.
Анализ
Уровень на котором обработанные данные служат источником для аналитических процедур, на основе задач бизнес-подразделений. Обычно к этому уровню непосредственно обращается API клиентской части, для получения осмысленных результатов обработки.
Ключевые характеристики DataLake
Duration: 10
Вариативность - подход к обработке на базе DataLake позволяет собирать данные любого формата и хранить их в специфичном для формата виде. Не завязан на структурированные языки запросов и структуры хранения.
Объемы хранения - позволяет реализовывать горизонтальную обработку данных за счет отдельного сервиса для хранения данных, который легко масштабируется горизонтально
Скорость роста данных - за счет горизонтального масштабирования может хорошо собирать слабозацепленные данные практически с любой скоростью, при росте зацепления система быстро усложняется.
Недостатки:
- вариативность:
- скорость низкая, сбор как правило основан на принципе "целостность в конечном итоге"
- дополнительные сложности в системах, основанных на транзакциях (например, платежные системы)
- объемы хранения:
- низкая плотность данных (частично решается применением механизмов сжатия, но это еще больше уменьшает скорость)
- скорость роста
- проблемы обработки сильнозацепленных данных (синхронная обработка), например, обработка "дельт" вместо "значений".
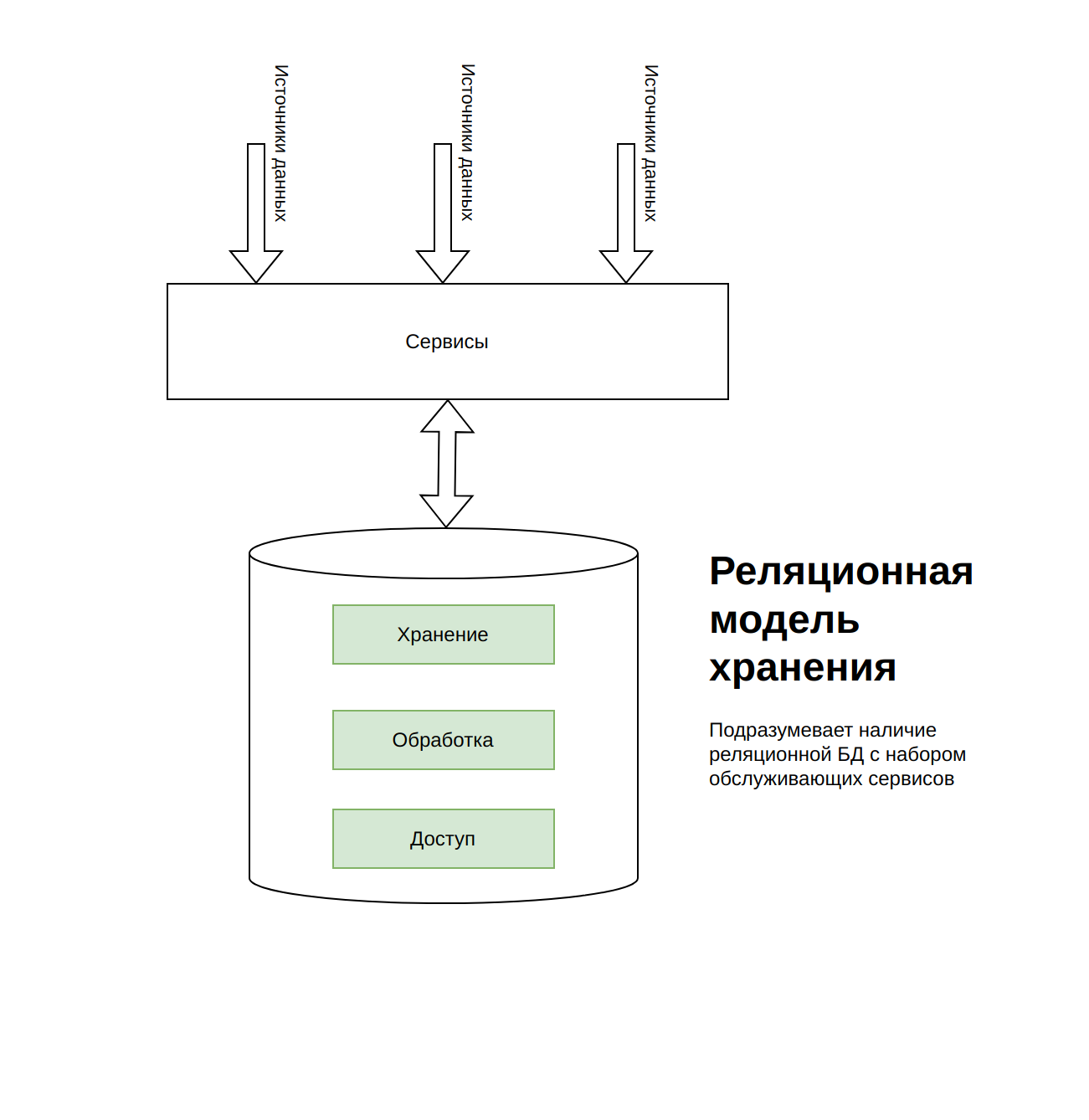
Хранилища (доступ от "Сбор" и "Обогащение"): - быстрые - обработка приближенного к реальному времени - управление по типу "оркестрация" - медленные - пакетная обработка (буферная) - управление по типу "ETL"
Варианты обработки: - Кластерная (hadoop) - Облака (AWS, Google и т.д.)